
Program comprehension is a concept of understanding a software to perform different software maintenance tasks.In recent years, the size of code base is increasing drastically which makes program comprehension difficult. To cope withthe demand, a lot of research works have been performed tounderstand how developers comprehend a program or code snippet and how to support developers so that they can easily start their assigned tasks. Different cognitive models are proposed in the literature to ease comprehension. Recently, studies to cluster execution paths of a call graph to aid overall program comprehension are going on. We argue that this structure can be used to aid top-down and bottom-up cognition model of program comprehension.
Motivational Example
To demonstrate how the hierarchical abstraction of a software system will work, we have created a sample Calculator program. The program takes two numbers as input, validates the inputs and prompts the user to input which operations they want to perform. Later, according to the input, addition, subtraction, multiplication, division can be performed. This is a brief functionality of the calculator program.
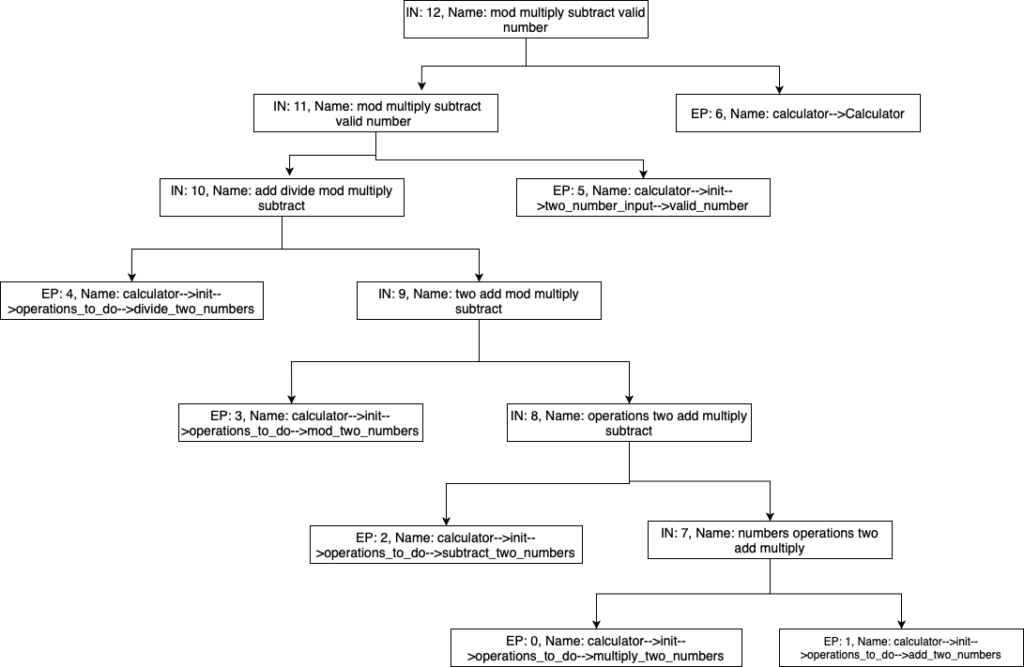
In the above figure, execution path 0 and 1 represents the functionality of multiply two numbers and adding two numbers respectively. For this two clusters, add and multiply is the two different job they are doing. Other functions of the two path is similar. So, the abstraction of these two executionpath are Intermediate node 7. Five keywords is picked as the abstraction of execution path 0 and 1. From the keywords of node 7, it is clear that descendent nodes do addition and multiply on two number.
Study Design
To hierarchically abstract a software system, multiple challenges exist. We have designed four study to facilitate the abstraction system to be meaningful.
Study 1 – Labeling abstraction nodes with different IR-based techniques
In this study, by mining concepts from source code entities (name of the function), we generate concept cluster tree which map low-level source code with concept to complement existing studies to facilitate more effective program comprehension for developers. We apply three different information retrieval techniques such as TFIDF, LDA, and LSI in various subject systems for naming the nodes with two variations (i.e., cluster naming by function names and cluster naming by words in function names) of the techniques. From our experiment, we found that among the techniques on average, TFIDF performs better with around 64% matching than the other two techniques LDA and LSI that reports 37% and 23% matching respectively from user naming for 12 use cases. Besides, the words in function name variant performs at least 5% better in user rating for all the three techniques on average for the use cases.
Study 2 – Supporting abstraction nodes with natural text and frequent patterns
In this study, we extend our previous work by providing support for nodes of the abstraction tree. We came up with two more supporting content. First, we used first line of docstring comments for each function to generate natural language texts summary for each node in the abstraction tree. Second, we mined sequential patterns from all execution paths which belongs to a node and provided this for the developers to better comprehend nodes. We conducted an empirical study to find the effectiveness of the proposed techniques. We find that providing the natural text summaries and mined patterns improve the comprehension ability of hierarchical abstraction tree.
Study 3 – Remove redundancy from Hierarchical Abstraction Tree, creation of Dataset with human label and comparison with Automated Dataset (In progress)
In the previous study, we tried to support nodes comprehension with function comments and frequent patterns in execution paths. During our manual investigation in the study, we found that as there are redundant overlapping execution paths the outcome of our information retrieval techniques are not performing to best of their capability. Moreover, for larger subject systems the tree become so large that it is almost unmanageable to explore. Inspired from the previous study, we take advantage of pattern mining algorithms to minimize the number of clusters in the tree and skip duplicate contents in the tree. This improve the output of information retrieval algorithms as redundant data are removed. In the next part, we manually label nodes as there is no human label available to compare with automated techniques.
Study 4 – Automated method comment generation (In progress)
During our 3rd study, we found that most of the function names do not have comment which hamper our approach to generate automated summary of nodes in abstraction tree. In this study, we tried to improve automated summary of methods using deep learning models.